Introduction
Recently, I had the opportunity to attend the Mobile World Congress 2026 in Barcelona. For those unfamiliar, it began as a trade show focused on the mobile communications industry, but over the years it has evolved into one of the world’s largest and most influential events in technology and connectivity.
At MWC, everything happens at once: product showcases, conferences, debates, and open panels. As expected, a large part of the conversation revolved around AI: companies announcing AI-powered products, talks covering investment, cybersecurity, and real-world applications.
One session in particular caught my attention: “AI in Action: Use Cases Across Cyber, Defence and Space”. As an engineer whose work spans aerospace, networks, and software systems, seeing how AI is shaping those fields was especially interesting.
But what stayed with me wasn’t a product or a statistic. It was three questions asked to the audience during the session, questions about risk, trust, and how organisations should approach AI.
I found myself agreeing with the winning answers. But my reasoning was shallow. I had opinions built from articles, discussions, and general exposure, but I couldn’t fully defend them. I understood pieces of the picture, but I couldn’t connect them.
And the gap became obvious when I tried. If AI systems are just mathematical models, they have no inherent notion of safety, intent, or understanding. And yet they appear to reason, follow instructions, and interact with the world. Something that “just predicts the next word” shouldn’t be able to do any of that, and yet here we are.
Those three questions deserved better answers than I could give. So I went back to basics.
This article is my attempt to build that understanding, and to bring you along for it. By the end, the answers to those three questions should feel a lot more grounded.
What is AI?
To answer those questions, we first need to understand what AI actually refers to.
AI is not what we usually think it is.
AI is a broad field of research. Within it, there is machine learning, and within it, deep learning.
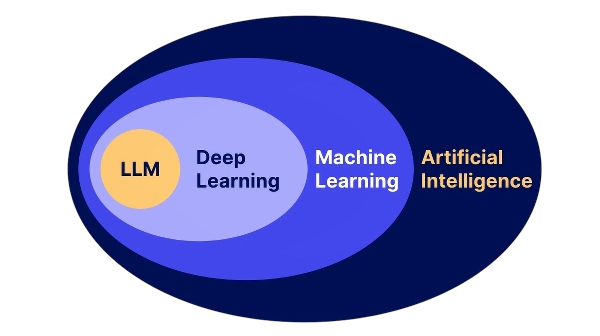
The systems we interact with daily, like ChatGPT, Gemini, Grok, or Claude, are a specific type of deep learning model known as Large Language Models (LLMs).
And despite all the hype, their core idea is surprisingly simple.
Overview
In the next sections, I’ll try to explain, at a very high level, how an LLM works. But before getting into tokenization, embeddings, or transformers, it helps to start with the core idea behind all of them.
At its core, a Large Language Model is a very sophisticated autocomplete engine running in a loop.
It receives text as input, processes it, and predicts what should come next. Then it adds a token (a word, part of a word, or even punctuation) to the existing text and repeats the process again and again until it forms a complete response.
That may sound almost too simple, but that loop is the foundation of everything that makes these systems feel intelligent.
A relatable way to see it is with a modern prompt. Imagine you ask an LLM:
Write a message telling my boss I’m sick and I can’t come into work
And you get the response:
Hi, I’m not feeling well and will need to take the day off.
At first glance, it looks like the model is “understanding” your intention and deciding what to write. But internally, what it is really doing is generating the response one token at a time.


The diagram shows this process as a loop. At each step, the model takes the full text so far, predicts the next token, and feeds that result back into itself.
In other words, it doesn’t write the message in one go, it builds it piece by piece.
But this raises a natural question.
What exactly is a “token” for the model?
Tokenization and Embeddings
At this point, I had never stopped to question how LLMs understand text. I just assumed they worked with words, more or less like we do.
But in reality, LLMs have no notion of words at all. They don’t “see” language the way we do, they only process numbers. Not words, not meaning, just numerical representations.
So how do we go from a sentence like:
Write a message telling my boss I’m sick
to something a model can actually work with?
The answer is a two-step process:
- Tokenization — breaking text into smaller pieces called tokens
- Embeddings — converting those tokens into numbers the model can process
Tokenization
Tokenization is very simple. For that, you need a dictionary and a piece of text. For simplicity, we will assume a token is equivalent to a word. This can be the case, although most real-world LLMs work slightly differently.
The first step is to define our dictionary. It is nothing more than a mapping between text and numbers. For example:
- Hello = 01
- Write = 02
- Message = 03
- …
The better the dictionary, the better the tokenization, since it can represent more words and expressions.
So take our example, after tokenization, it would look something like this:


At this point, you might wonder:
What happens if a word is not in the dictionary?
In practice, modern models don’t rely purely on whole words. Instead, they break text into smaller pieces, like parts of words or syllables.
This way, even if the model has never seen a specific word before, it can still represent it as a combination of smaller known pieces.
Now, if we look at the result of tokenization, we end up with numbers like:
02, 56, 03, …
But a single number by itself doesn’t carry much meaning. It’s just an identifier.
So how does the model go from numbers to something meaningful?
This is where embeddings come in.
Embeddings
Embeddings might sound complex, but the idea behind them is quite intuitive.
Instead of representing a token as a single number, the model converts it into a list of numbers.
Each of these numbers captures a small aspect of the token’s meaning. Taken together, they form a richer representation.
So instead of:
Write → 02
we get something like:


In this example, there are only 3 numbers, but in practice this vector (or list of numbers) can have hundreds or even thousands of values.
At this point, you might wonder how a word can be turned into a meaningful set of numbers.
The short answer is that the model learns these representations from large amounts of data during training, adjusting them so that words used in similar contexts end up with similar numerical representations.
The exact process behind this is mathematical and more involved, but for our purposes, it’s enough to understand that these numbers are learned in a way that captures meaning.
This helped me understand the answers to one of the questions presented in the session. Two of them, in different ways, were pointing to the same underlying idea: quality, of the data, and therefore of the model itself.
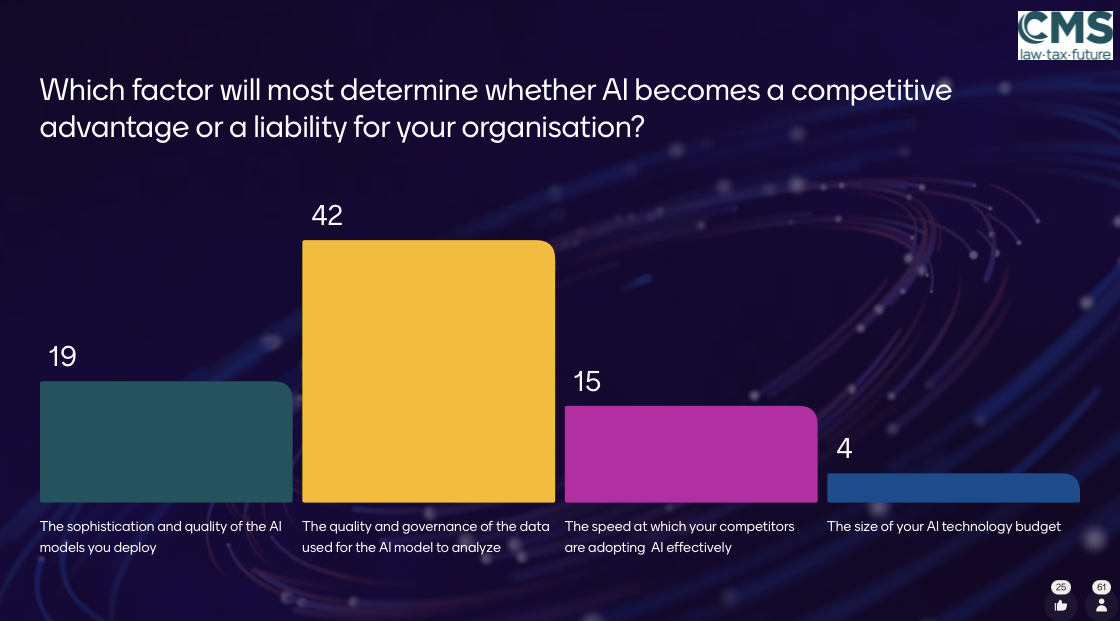
After understanding tokenization and embeddings, this made much more sense.
If every word is transformed into a numerical representation, then the quality of those representations depends entirely on the data the model was trained on.
In other words, the model is only as good as the data it learns from.
Better data leads to better representations.
And better representations lead to better outcomes.
This has two important implications:
- The training data determines how well the model understands language
- The input you provide determines how well it can respond in a given situation
If the data is poor, noisy, or biased, then the resulting representations will also be poor, and the model’s output will reflect that.
So far, we have managed to understand how LLMs actually see text and words, the next step is making the LLM understand the context of how the word is being used and remember information in some way.
The Transformer
We’ve seen how text becomes numbers, and how those numbers can represent meaning.
But there is still a key question:
How does the model actually use that information?
This is where the transformer comes in.
The transformer is the part of the model that processes these embeddings and allows the LLM to understand context and relationships between words.
You can think of it as a system that takes all these numbers and updates them based on how the words relate to each other in context.
Because meaning doesn’t exist in isolation.
For example:
I park the car across the street
I enjoy going to the park
The word park means something completely different depending on the surrounding words.
So the model needs a way to look at all the words together and understand how they influence each other.
There is another important aspect as well: consistency across the sentence.
If the model sees:
Wizard Harry
it should be able to relate that to:
Harry Potter
And if it sees Harry Potter, it should understand that it refers to a wizard.
This doesn’t mean the model has memory in the human sense, but it does maintain and update a representation of the entire context as it processes the text.
These two ideas, understanding context and maintaining a coherent representation, are mainly handled by two components inside the transformer:
- Attention → determines which words are most relevant and how they influence each other’s meaning
- Feed-forward layers (or Multilayer Perceptron) → refine and transform the internal representation
But you don’t need to focus on the names.
At a high level, you can think of it as:
understanding context and refining meaning
Attention
Attention is what allows the model to determine which words are most relevant, and how they influence each other’s meaning.
Instead of treating every word independently, the model learns to combine information from different parts of the sentence to build a more accurate representation.
At a low level, this means the numerical representation of each word is updated using information from other words in the sentence.
For example, in:
I enjoy going to the park
the model will associate park more strongly with enjoy and going. This shifts its internal representation toward something that resembles a place or location.
On the other hand:
I park the car across the street
the model will associate park more strongly with car, across, and street. In this case, its representation shifts toward something closer to an action or verb.
This doesn’t mean the model explicitly “knows” what a place or an action is. Instead, these relationships subtly change the numerical representation of the word, making it more similar to other words used in similar contexts.
In other words, attention doesn’t just highlight important words, it allows words to reshape each other’s meaning.
This is what allows the model to capture meaning based on context.
Feed-forward layers
Attention tells the model how words relate to each other. But knowing that park is closer to car and street than to enjoy and going is only half the work. The model still needs to do something useful with that signal.
This is where feed-forward layers come in. If attention is about relationships, feed-forward layers are about patterns. For each word, they take the updated representation and ask implicit questions like: is this a place or an action? Is this concept positive or negative? Does this fit the pattern of a technical term, a name, a verb?
They don’t ask these questions explicitly, there’s no code that says “check if this is a noun.” Instead, the model has learned through training that certain patterns of numbers tend to correspond to certain kinds of meaning, and the feed-forward layers push each representation toward those learned patterns.
Think of it like this: attention figures out the context, feed-forward layers draw the conclusions from it.
Transformer Output
At a very low level, all of this is still just numbers being adjusted, the internal representations (which started as embeddings) are continuously updated at each step to reflect context and meaning.
At the end of these processes (attention and feed-forward) the model doesn’t directly produce a word.
Instead, it produces a set of probabilities over all possible next tokens.
Each token is assigned a likelihood based on the patterns the model has learned, and one of them is selected as the next step in the sequence.
For example, given a prompt, the model might internally assign probabilities like:
- “Hi” → 40%
- “Hello” → 25%
- “I’m” → 15%
- “Sorry” → 10%
This is what ultimately drives the generation process:
not reasoning about what is correct, but selecting what is most likely.
Putting it all together
At this point, we can put all the pieces together and see how an LLM generates text.
Starting from a simple input like:
Write a message telling my boss I’m sick
the process looks roughly like this:
- The text is broken into tokens
- Tokens are converted into embeddings (numbers that represent meaning)
- These embeddings are processed by the transformer
Inside the transformer, the same two steps happen repeatedly:
- Attention helps the model determine how words relate to each other and shape their meaning
- Feed-forward layers refine and transform that understanding
Between these steps inside the transformer, there are additional operations (like normalization and residual connections) that help stabilize training, but they don’t change the high-level idea.
This process is repeated many times across multiple layers, gradually building a richer and more contextual representation of the text.
At the end of this process, the model produces a set of probabilities over possible next tokens, and one of them is selected.
That token is added to the sequence, and the whole process runs again.
This is illustrated in the diagram below:


Even though the system feels complex, the core loop is still the same:
understand context → refine meaning → predict next token → repeat
Now that we understand how these systems work, something important becomes clear.
At each step, the model is not choosing the “correct” next word.
Instead, it is selecting from a set of probabilities based on patterns it has learned from data.
These probabilities come directly from the patterns the model learned during training.
This means the model is not reasoning about what is true or correct.
It is simply generating what is most likely to come next.
Understanding this also helps explain another question that was raised during the session:
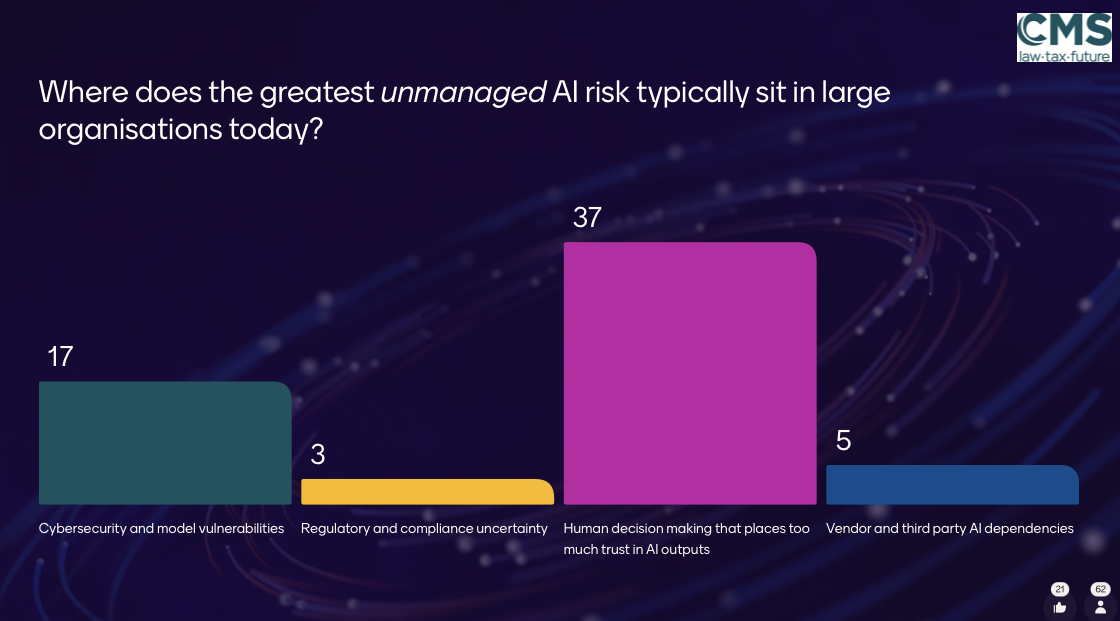
Looking at the results, two answers stood out.
The dominant answer, human decision-making that places too much trust in AI outputs, points to something we’ve already seen: the model isn’t reasoning or verifying. It generates what is most probable. A response can sound confident and structured while still being wrong.
But the second answer is equally worth noting: cybersecurity and model vulnerabilities. Because once you understand that these systems operate on learned patterns and probabilities, it becomes clear that they can be influenced by specific inputs in unexpected ways. Carefully crafted prompts can push the model toward unintended or unsafe outputs.
These two risks aren’t unrelated. In both cases, the underlying problem is the same: the model is optimizing for likelihood, not truth or safety. One risk sits with the user, the other with the attacker, but the root cause is identical.
These systems are powerful tools, but they do not understand, verify, or guarantee correctness.
And this is exactly why so much effort goes into shaping how these models behave before they are ever used.
From Raw Model to Useful Assistant
So far, we’ve seen how a Large Language Model processes text and generates responses.
But this raises another important question:
If the model is simply predicting the most likely next token, how does it produce answers that feel helpful, structured, and aligned with what we expect?
The answer is that the model is not used in its raw form.
Before we ever interact with it, it goes through multiple stages of training and refinement.
At a high level, this process has two key phases:
- Pretraining — where the model learns language patterns from large amounts of data
- Fine-tuning — where the model is guided to behave in a more useful and aligned way
This is what transforms a system that only predicts text into something that feels like an assistant.
Pretraining
The first step is pretraining.
This is where the model learns the structure of language by training on extremely large amounts of text data.
Public information suggests that modern models are trained on datasets that include a mixture of books, articles, websites, video transcriptions, code, and more, amounting to hundreds of billions or even trillions of words.
During this phase, the model is not taught specific tasks.
Instead, it learns by doing one simple thing over and over again:
predicting the next token
By repeating this process across vast amounts of data, the model learns:
- grammar and sentence structure
- relationships between words
- patterns of reasoning and explanation
Over time, the model adjusts its internal numbers so that better predictions become more likely.
This is where most of the model’s “knowledge” and language ability comes from.
But at this stage, the model is still not particularly useful as an assistant.
It can generate text, but it is not necessarily helpful, safe, or aligned with what a user expects.
Fine-tuning
To make the model more useful, it goes through a second phase: fine-tuning.
Here, the goal is not to teach language, but to guide behavior.
This is typically done using curated datasets and human feedback, where the model is trained to produce responses that are more helpful, safe, and aligned with instructions.
There are different ways to fine-tune a model, but two common approaches are:
- Classification-style tuning — where the model learns to categorize or select correct outputs
- Instruction tuning — where the model learns to follow prompts and behave like an assistant
For example:
-
In a classification setting, the model might be trained to take a sentence like:
“This product is terrible”
and classify it as negative sentiment -
In an instruction setting, the model might be trained to respond to a prompt like:
“Summarize this email”
and produce a concise, structured response
This is what allows the model to respond to requests like:
“Write a message telling my boss I’m sick”
in a structured and appropriate way.
However, it’s important to remember that fine-tuning does not fundamentally change how the model works.
It is still predicting the most likely next token, just within a more guided and constrained behavior.
System prompts
Finally, there is one more layer that shapes how the model behaves: the system prompt.
This is not part of training, but something added at runtime.
Before your input is processed, the model is typically given hidden instructions that define its role and behavior.
For example, it might receive something like:
“You are a helpful assistant. Respond clearly and professionally.”
This means the model is not just continuing your input, it is continuing the entire context, including these instructions.
This is why the output feels structured and intentional, rather than like simple autocomplete.
Together, pretraining, fine-tuning, and system prompts shape how the model behaves.
A useful way to think about this is through roleplay.
When an actor plays a character, they don’t become that character. They have learned the script, the mannerisms, the context, and they use all of that to produce a convincing performance. But underneath, they are still themselves.
A fine-tuned model with a system prompt works similarly. It has been trained on vast amounts of human language and thought, then guided to behave in a specific way, and given a role to play at runtime. When you talk to a helpful assistant, a customer service bot, or a coding companion, you are interacting with the same underlying mechanism playing a different character.
This is why these models can feel so natural to talk to. They are not pretending to understand. They are simply very good at sounding like someone who does.
But even with all of this, the underlying mechanism remains the same:
the model is still predicting the most likely next token


At this point, everything starts to connect.
These systems are not intelligent in the way we often assume. They are the result of data, training, and careful guidance, all built on top of a simple underlying mechanism.
And that is exactly where the challenge lies.
The more capable these models become, the easier it is to rely on them without fully understanding how they work or where their limitations are.
Which brings us to the final question raised during the session:
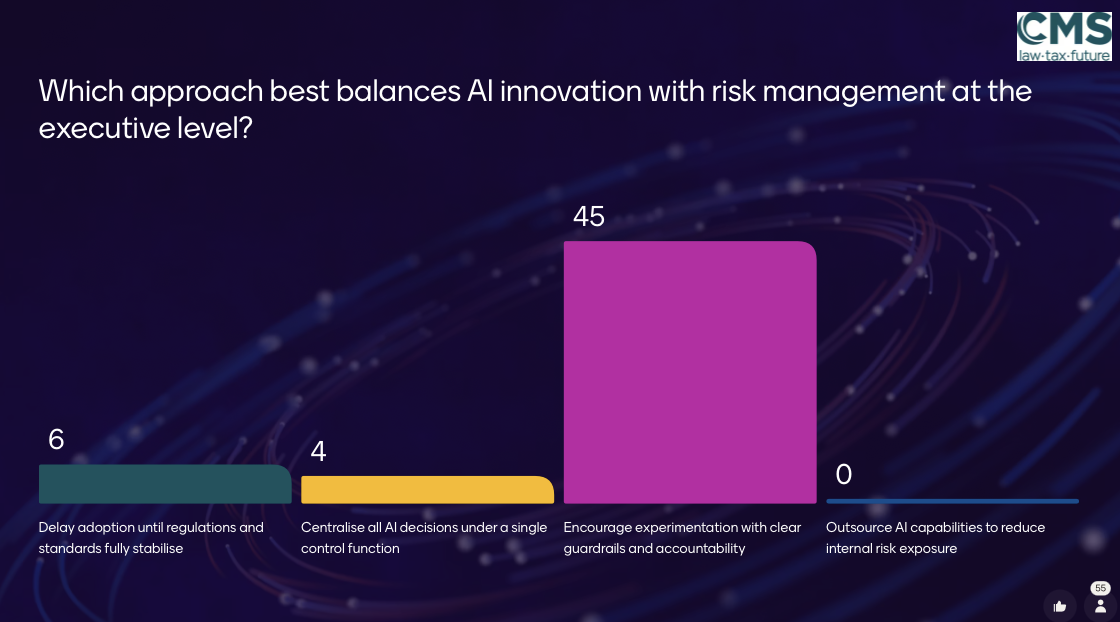
There was a clear winner:
Encourage experimentation with clear guardrails and accountability
And honestly, that feels exactly right.
These systems are powerful tools, but they are still just tools. They require an operator who understands their limitations and takes responsibility for how they are used.
The fact that they appear more capable does not remove the need for supervision. If anything, it makes it more important.
Balancing innovation and risk is not about limiting these systems.
It is about using them consciously.
Final thoughts
This article is not meant to be a complete or perfectly accurate explanation of how LLMs work.
It is my attempt to understand them, and to share that understanding in a way that others can follow, even without a technical background.
Because the reality is that these tools are already part of everyday life.
People across all fields are using them.
And that’s not a bad thing.
But it does make it important to at least have a rough idea of what we are interacting with.
For me, learning how these systems work didn’t remove the sense of magic.
It just replaced blind trust with informed curiosity.
I now see both the limitations and the possibilities more clearly.
And that, in itself, changes how I use them.
Understanding how these systems work doesn’t make them less impressive. If anything, it raises a bigger question.
At a very abstract level, both LLMs and humans are systems that learn patterns and make predictions. Whether there is something fundamentally different between us, or whether it is just a matter of scale and time, is a question I don’t think anyone can answer confidently yet.
That’s a much bigger discussion, and one I’m still thinking about.
If this article helped clarify things, or at least sparked a bit of curiosity, then it did its job.
If you want to go deeper
If you’re interested in learning more, I highly recommend:
- Build a Large Language Model (From Scratch) by Sebastian Raschka
- The excellent visual explanations by 3Blue1Brown
- A collection of known system prompts for popular models
Note:
The exact way these mechanisms work internally is still an active area of research.
The transformer architecture was introduced in the paper Attention Is All You Need, developed at Google.
While attention itself is well understood mathematically, behaviors that resemble “memory” are less straightforward. Research suggests that models do not store facts explicitly, but rather reconstruct them from patterns in their internal representations.
A good example of this is explored in Fact finding: attempting to reverse engineer factual recall on the neuron level, which investigates how models retrieve information without having a traditional memory.